Graphify : diviser par trois tes tokens Claude Code en 30 secondes
Le repo open-source qui transforme ton projet en knowledge graph local pour que Claude Code, Cursor et Codex naviguent ton code au lieu de le re-grep à chaque session. 70% de tokens en moins par session, install en deux commandes.

Le vrai problème, ce ne sont pas tes usage limits
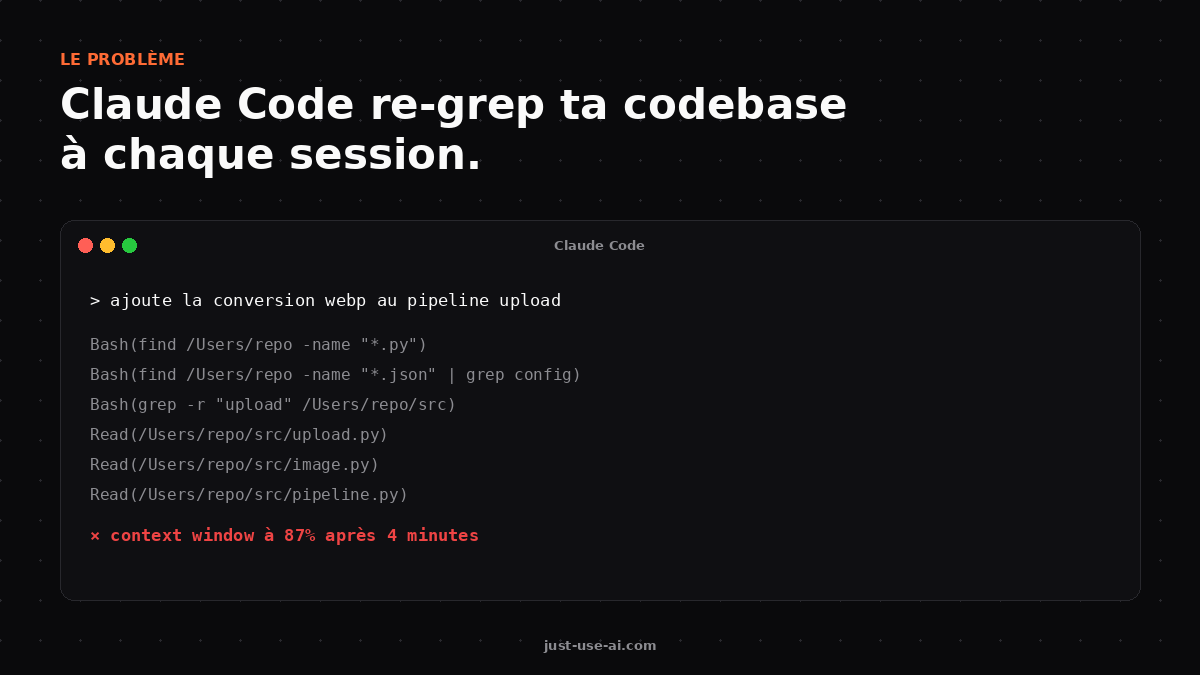
Tu codes avec Claude Code tous les jours. Et tu connais cette sensation : tu lances une session, tu demandes à Claude un truc simple, et trois minutes plus tard ton context window est déjà à quatre-vingt-sept pour cent. Tu te dis que tu as atteint les usage limits trop vite, encore une fois.
Mauvais diagnostic.
Le vrai problème, ce n'est pas Anthropic qui serre la vis. C'est Claude Code qui re-grep ta codebase à chaque session. Find. Grep. Read. Find. Grep. Read. À chaque nouvelle question, il refait le même travail d'exploration parce qu'il n'a aucune mémoire structurée de ton projet. Résultat : tu paies trois fois pour le même travail, et tu finis ta session avant d'avoir vraiment commencé.
Ce que Graphify change
Graphify, c'est un skill open-source qui transforme ton projet entier en knowledge graph local. Tu tapes une commande dans Claude Code (ou Cursor, ou Codex, ou Gemini CLI, ou n'importe quel assistant que tu utilises) et il scanne tout : ton code, tes docs, tes PDFs, tes schémas SQL, tes vidéos, tes images.
Au bout de trente secondes, tu as trois fichiers :
- Un
graph.htmlque tu ouvres dans ton navigateur pour explorer visuellement ton projet - Un
GRAPH_REPORT.mdqui liste les concepts centraux, les connexions surprenantes et les questions que le graph peut répondre - Un
graph.jsonque Claude interroge directement au lieu de re-lire tes fichiers
À partir de là, Claude ne grep plus. Il navigue. Et c'est exactement ce qui fait la différence sur le compteur de tokens.

Les chiffres
Cinquante-trois mille deux cents étoiles GitHub, Y Combinator S26, plus de cinq mille forks, version huit en développement actif. Le projet est porté par Safi Shamsi et tourne sur 31 langages de code différents extraits localement via tree-sitter (donc zéro API call pour la partie code).
Mais le chiffre qui compte vraiment pour toi, c'est celui-ci : soixante-dix pour cent de tokens en moins par session quand Claude query un knowledge graph au lieu de re-grep ta codebase. Concrètement, une session qui consommait 180 000 tokens avant peut tomber à 54 000 tokens après. Tu fais trois fois plus de travail avant d'atteindre tes usage limits.

Comment ça marche, vraiment
Le pipeline est en deux étages :
Étage local (zéro API call). Tree-sitter parse ton code AST et construit la structure du graph : fonctions, classes, dépendances, imports, appels. C'est rapide, c'est gratuit, c'est privé. Aucune ligne de ton code ne quitte ta machine.
Étage sémantique (via ton LLM). Pour les docs, les PDFs, les images, les vidéos, Graphify utilise le modèle de ton assistant pour extraire les concepts et les relations. Si tu es sur Claude Code, ça utilise ta subscription Claude existante. Pas de clé API supplémentaire à gérer.
Une fois le graph construit, ton assistant a accès à des opérations structurées : query_graph pour poser une question en langage naturel, get_neighbors pour explorer un concept, shortest_path pour trouver le lien entre deux entités. C'est ça qui fait l'économie de tokens : au lieu de re-lire dix fichiers pour comprendre comment l'auth se connecte à la base de données, Claude demande le shortest path et reçoit la réponse en quelques nodes.
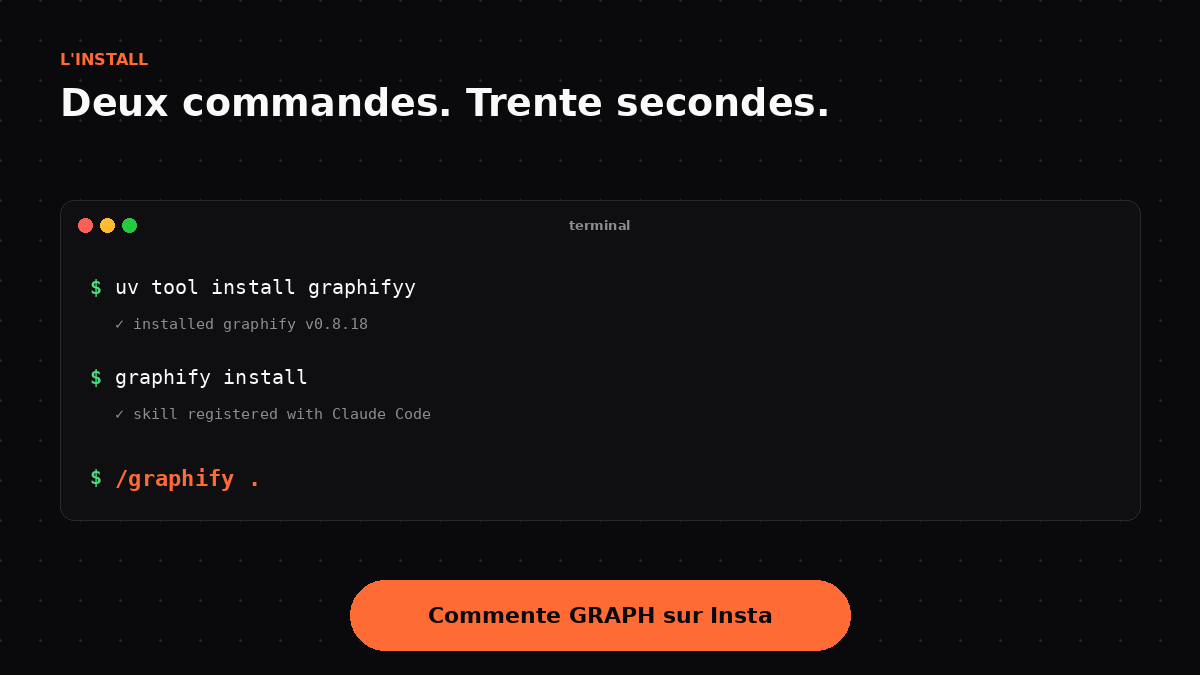
Le setup, en deux commandes
L'install prend trente secondes chrono. Tu as besoin de Python 3.10 ou plus et de uv (le package manager d'Astral qui remplace pip).
uv tool install graphifyy
graphify install
Première commande : tu installes le binaire. Deuxième commande : tu enregistres le skill auprès de ton assistant (Claude Code par défaut, mais ça marche aussi avec --platform codex, --platform cursor, --platform gemini, etc.).
À partir de là, dans n'importe quel projet, tu tapes /graphify . et ton assistant construit le graph du dossier courant. Tu peux aussi pointer un dossier spécifique avec /graphify ./src si tu veux indexer seulement une partie de ton repo.
Les use cases qui changent ta vie
Trois scénarios concrets où Graphify fait la différence pour un dev solo ou un freelance qui code avec l'IA :
Onboarding sur un repo client que tu ne connais pas. Tu reçois un projet legacy de 80 000 lignes. Sans Graphify, tu passes deux jours à demander à Claude "explique-moi comment ça marche" et il re-grep tout à chaque question. Avec Graphify, tu fais /graphify . une fois, tu ouvres le GRAPH_REPORT.md, et tu as immédiatement la carte des "god nodes" (les concepts par lesquels tout passe) et des connexions surprenantes entre modules.
Refactor d'un module critique. Tu veux changer ton système d'auth, mais tu ne sais pas tout ce qui en dépend. Au lieu de grep "auth" partout, tu lances graphify query "qu'est-ce qui dépend de UserService ?" et tu reçois la liste exacte des nodes connectés, avec leur niveau de confidence (EXTRACTED, INFERRED, ou AMBIGUOUS). Tu sais ce que tu peux casser avant de casser.
Maintenir un graph d'équipe partagé. Tu commit graphify-out/ dans ton repo Git. Toute l'équipe pull et a immédiatement la même carte. Quand quelqu'un commit, un git hook auto-rebuilde le graph (en mode AST only, sans API call). Pas de divergence, pas de re-extraction manuelle.
Les limites à connaître
Soyons honnêtes : Graphify n'est pas une baguette magique. Si ton repo est tout petit (moins de 1000 lignes), tu n'auras pas de gain notable, Claude peut tout charger dans son context sans souffrir. Le ROI vraie commence sur des projets de 10 000 lignes et plus, et explose au-delà de 50 000 lignes.
Autre limite : la partie sémantique (docs, PDFs, images) passe par ton LLM, donc elle coûte des tokens à l'extraction initiale. C'est un coût upfront que tu amortis sur les sessions suivantes. Compte cinq à dix minutes d'extraction et un coût équivalent à une session Claude bien remplie, en échange de semaines de gain sur les sessions futures.
Pour aller plus loin
Le repo officiel : github.com/safishamsi/graphify. La doc d'architecture est dans ARCHITECTURE.md du repo, elle explique en détail comment le graph est construit et comment la communauté détecte les clusters (algo de Leiden).
Si tu veux pousser plus loin, Graphify expose aussi un serveur MCP que tu peux brancher à n'importe quel client compatible. Tu lances python -m graphify.serve graphify-out/graph.json et tu as un endpoint structuré que Claude (ou n'importe quel autre LLM) peut interroger directement.
Et pour les freelances qui jonglent entre plusieurs repos clients : la commande graphify global add te permet de construire un graph cross-projet qui couvre tous tes repos enregistrés. Tu peux poser une question qui traverse plusieurs codebases d'un coup, sans changer de contexte mental.
Le bottom line : tes usage limits ne sont pas une fatalité. Le problème, c'est la façon dont ton assistant explore ton code. Donne-lui une carte, il arrête de marcher au hasard.
Accède aux ressources gratuites
Vidéos, guides, templates et outils pour automatiser ton quotidien avec l'IA. Laisse ton email — accès immédiat, à vie.
✓ Pas de spam · ✓ Accès gratuit à vie · ✓ Désinscription en 1 clic
On utilise ton email pour t'envoyer la ressource et nos guides IA. Tu peux te désinscrire à tout moment. Voir notre politique de confidentialité.